0. 前言 ·
本实验为 MIT6.s8081 的第十个实验,主题为 mmap 相关。实验要求实现简化版本的 mmap/munmap 。
1. 背景知识 ·
mmap 为 virtual memory 的扩展应用之一。通过将文件映射到 user 的 virtual memory address 中,使得 user 可以通过内存读写操作来进行文件读写。所以 mmap 涉及到 内存和 文件系统两部分。
要正确实现 mmap,首先要知道 mmap 的预期行为有哪些。查看 linux 和 mmap 相关系统调用:
mmap 相关函数有两个:
1 | void *mmap(void *addr, size_t length, int prot, int flags, int fd, off_t offset); |
mmap 执行映射:
- addr, 要映射到哪儿的 hint(实际上并不一定映射到此处,对于本 lab 来说,addr 始终为 0,由内核选择要在 user vm addr 的哪个位置进行映射)
- length, 映射的长度。 可小于文件的 size, 等于文件的 size,或者超过文件的 size。如果超过了文件的 size,超出的部分填充为 0.
- prot, 对映射的区域的 protection 属性,本 lab 仅需支持 PROT_READ 和 PROT_WRITE。前者代表可读,后者代表可写。
- flags,映射的方式是什么。本 lab 仅需支持 MAP_SHARED 和 MAP_PRIVATE。 两者的区别如下:
- MAP_SHARED: Share this mapping. Updates to the mapping are visible to other processes mapping the same region, and (in the case of file-backed mappings) are carried through to the underlying file. 即更新对其他 process 可见,更新会写会被映射的文件。
- MAP_PRIVATE: Create a private copy-on-write mapping. Updates to the mapping are not visible to other processes mapping the same file, and are not carried through to the underlying file. It is unspecified whether changes made to the file after the mmap () call are visible in the mapped region. 即更新对其他 process 是不可见的,更新不会写回被映射的文件,更新采用都会在自身独有的 copy 上执行。
- fd, 要映射的 file 的 fd。
- offset, file 的 offset,本 lab 始终为 0.
munmap 取消映射:
-
addr, 要取消映射的首地址。 该地址不一定等于 mmap 返回的地址。所以取消的地址范围可能不是 mmap 中的地址范围。对于本 lab 而言,仅需支持三种情况的 munmap, 如下图:
对于区间中间位置段,留下一个 "hole" 的情况,不予考虑。
-
length: 需要取消映射的范围长度。

另外需要注意的是,执行 mmap 时,并未分配实际的物理页,mmap 采用了 lazy allocation 的方案,映射只是更改了页表,后续通过 page fault 来添加需要映射的 page。
2. 实现 ·
首先添加 mmap 和 munmap 系统调用,下面仅说下签名:
1 | char *mmap(void *addr, int len, int prot, int flags, int fd, int off); |
1. 基本数据结构 ·
接着实现 vma 相关结构体,用于表示一个 mmap 的映射区:
1 |
|
一个 vma_aera 代表一次映射。由于 xv6 内核不支持内核分配器(即内核的 malloc), 模仿 ftable,实现一个 vma_table,表示全局可用的的 vma 结构:
1 | struct |
完成对 vma 的分配,释放,初始化函数:
1 | void |
现在 xv6 支持并发的分配和释放 vma。 接下来来看看如何实现 vma:
每个进程都有自己的 vma 映射,且可能有多组映射,因为一个进程 mmap 多次,所以更改 proc 结构,添加 vma 支持:
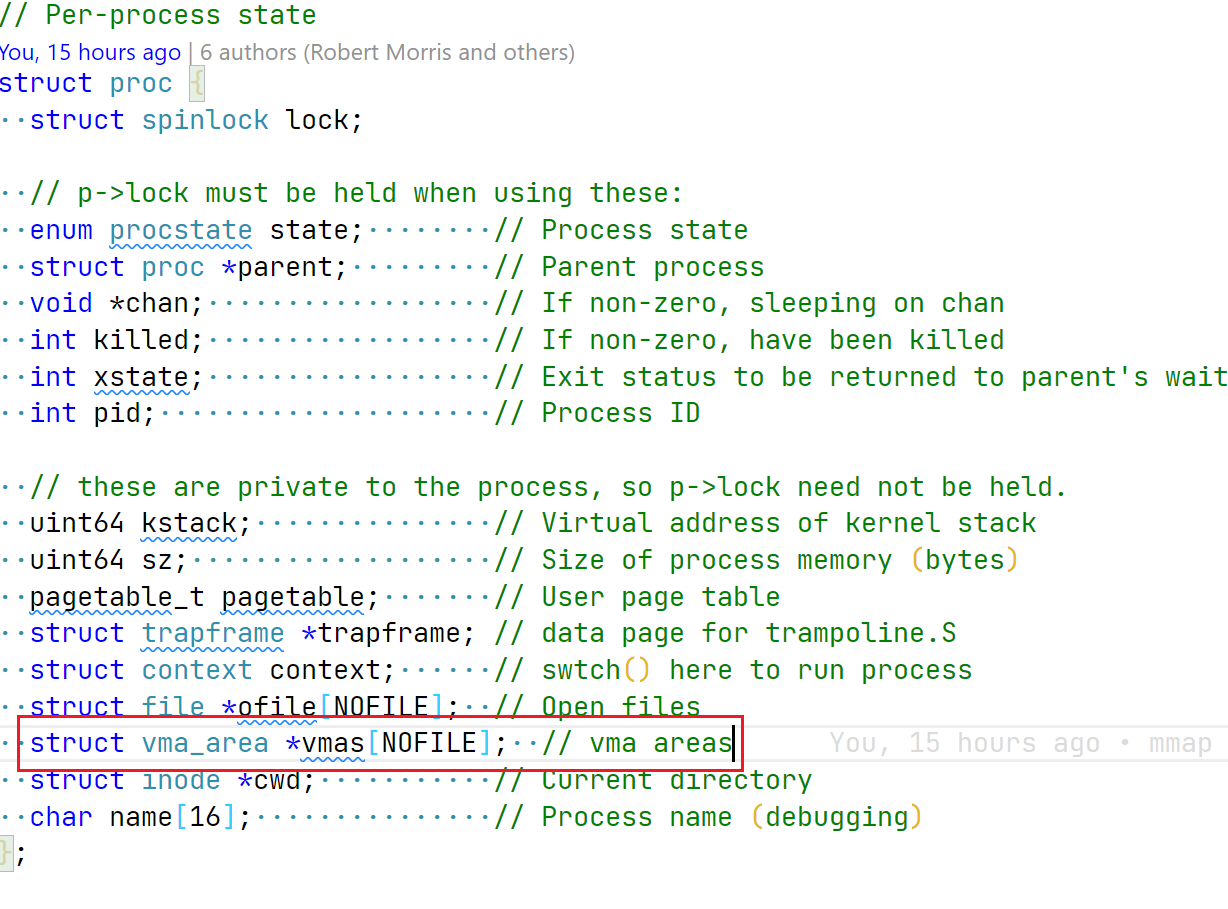
image-20220609132523318
2. sys_mmap·
以上添加了必须的数据结构,现在来完成 mmap 主体逻辑:
1 | // char *mmap(void *addr, int len, int prot, int flags, int fd, int off); |
主要逻辑为:‘
- 获取传入参数,因为本 labaddr 始终为 0,所以从第一个参数开始获取。
- 做一系列的合法性检查。比如传入的 prot 包含 PROT_READ, 则打开的文件也必须支持 read。 唯一的注意点是,** 如果 file 为 readonly, 但是 map 的 flag 为 MAP_PRIVATE,prot 为 PROT_WRITE, 此时也可以写入的。** 因为这样的映射组合,并不会修改到底层的文件,所有的修改都在进程自己的拷贝副本上进行。
- 分配 vma,并执行初始化。内核需要在进程空间中找到一个合适的连续地址空间,用于完成本次映射请求,找到的地址空间首地址应该是 page-aligned 的, 如果不是 page-aglined 的,后续的 page_fault_handler 中会出现错误。比如当前映射的首地址为 2K, 现在要访问的地址也是 2K, 对于第一次 load page 来说,会出现 page fault, 在 page_fault_hanlder 中,懒加载的 page 需要按照 page-aligned 的方式加载 page, 所以懒加载的页地址为 0K-4K-1。其中 0K-2K-1 这部分并没有做任何映射,所以会出现问题。
- 最后在 proc 中找到合适的 vma slot, 存放 vma 结构即可。
第三步中,寻找合适的连续地址空间,采用的是 lazy_growproc 的方式来完成:
1 | // Increase proc used addr space without allocating physical pages |
3. page_fault_handler·
至此完成了 sys_mmap, user app 执行 mmap 后,可能会对 map 的 page 执行 read/write 操作,此时会触发 page_fault, 下面是 page_fault_handler 代码:
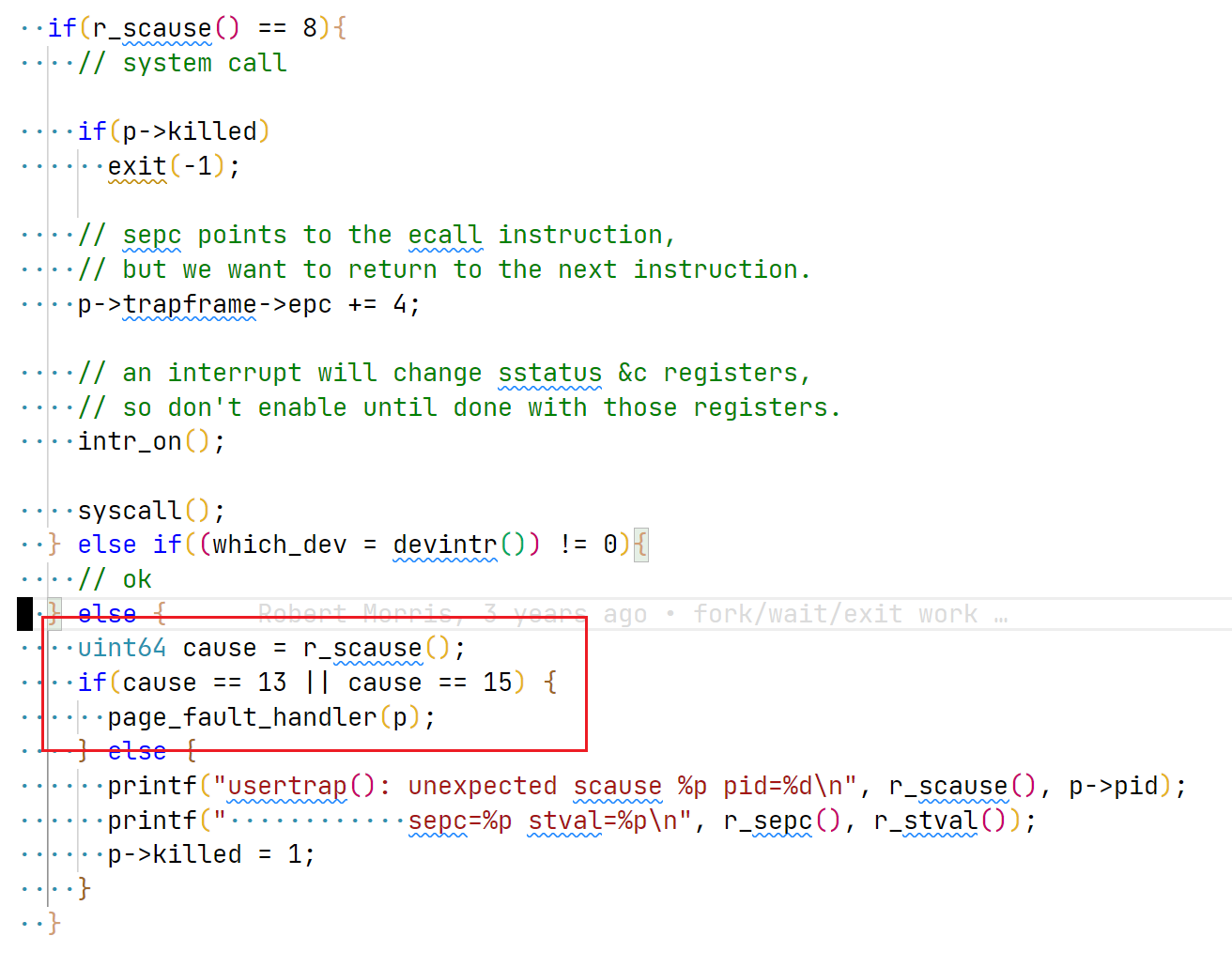
image-20220609133616808
1 | // mmap allocate physical memory lazily. |
这部分的工作为:
- 执行简单的合法性校验:访问 va 是否超过 process 的最大申请内存地址边界
- 找到包含 va 的 vma 结构。
- 分配实际的物理页
- 注入对应的文件内容。这里的注意点是,有可能 mmap 传入的 map length 是大于 file size 的,对于超过 file size 部分,全部填充为 0。
- 最后,向页表中添加这个物理 page 的映射。
注意,我个人的实现中,只要出现了 page fault,就单独分配了物理页给进程,但实际上 linux 中的实现,如果 flags 为 MAP_SHARED,则并不需要单独分配物理页,直接将映射绑定到 page cache 中即可,这样可以减少一次页的拷贝,提升性能。 如果 flags 为 MAP_PRIVATE, 则采用 COW 机制。 更多关于 Linux 的 mmap 描述,可参考:这里
上述代码使用到的 vmalookup 函数如下:
1 | // find the vma slot refering to a vma structure which contains |
代码逻辑很简单,循环遍历 p 的 vma 结构,找到包含 va 的 vma。 之所以采用二级指针,是因为后续的 sys_munmap 中会使用到。
4. sys_munmap·
现在来看看取消映射的代码:
1 | uint64 |
上述代码完成:
- 合法性检验
- 找到包含 addr 的 vma
- 对于 MAP_SHARED flag 的 map,需要将写入的数据,回写至文件,所以执行加解锁处理和文件写入。 由于仅需对 DIRTY_PAGE 进行写入,所以添加了
*pte & PTE_D的判定。 - 取消页映射
- 更新 vma 结构:
- 如果释放的是整个 vma 所代表的的地址空间,则释放 vma 结构
- 如果释放的开头 / 结尾区间,则更新 vma 结构即可,无需释放
5. 其他 ·
调整 uvmunmap, 用于支持 lazy allocation:
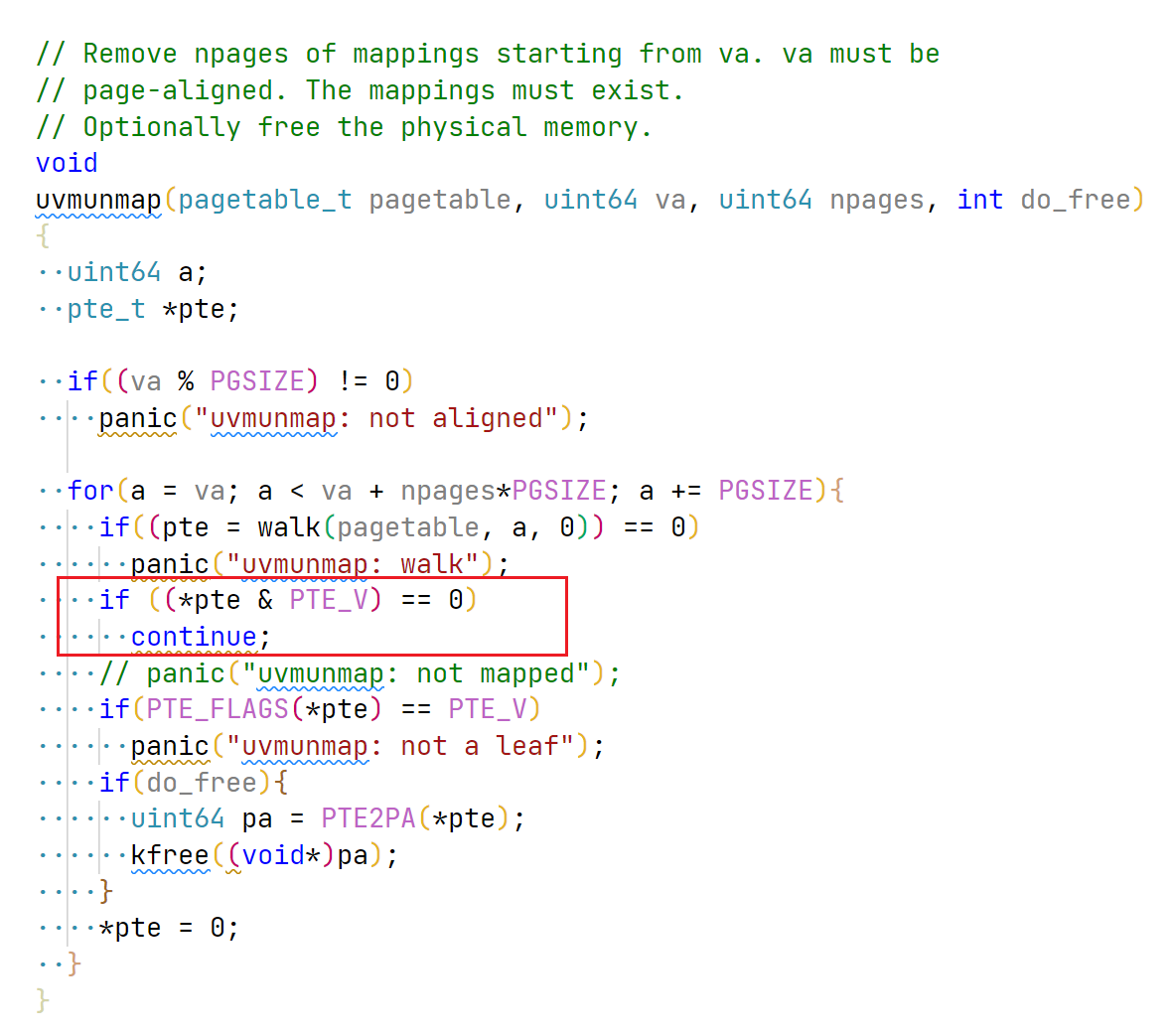
image-20220609135201008
调整 fork, 将父进程的 vma 继承给子进程:
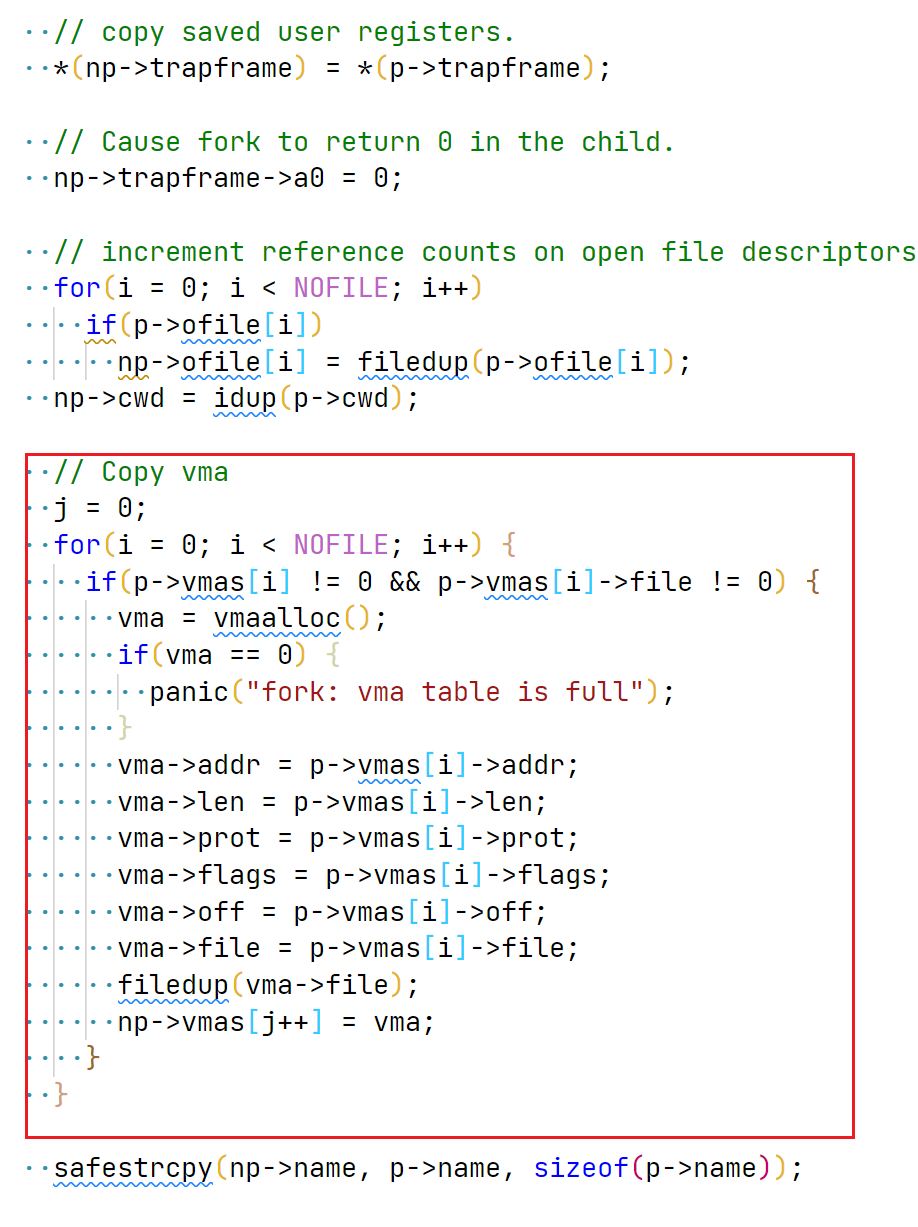
image-20220609135252478
调整 allocproc, 完成 proc vma 的初始化:
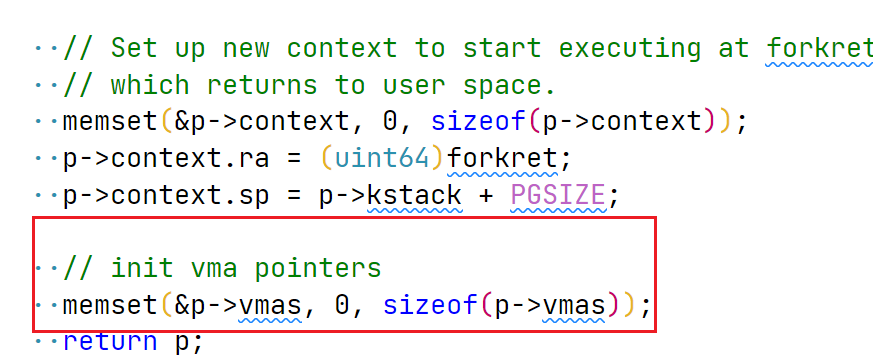
image-20220609135450269
调整 uvmcopy, 以支持 fork 时的页表复制。
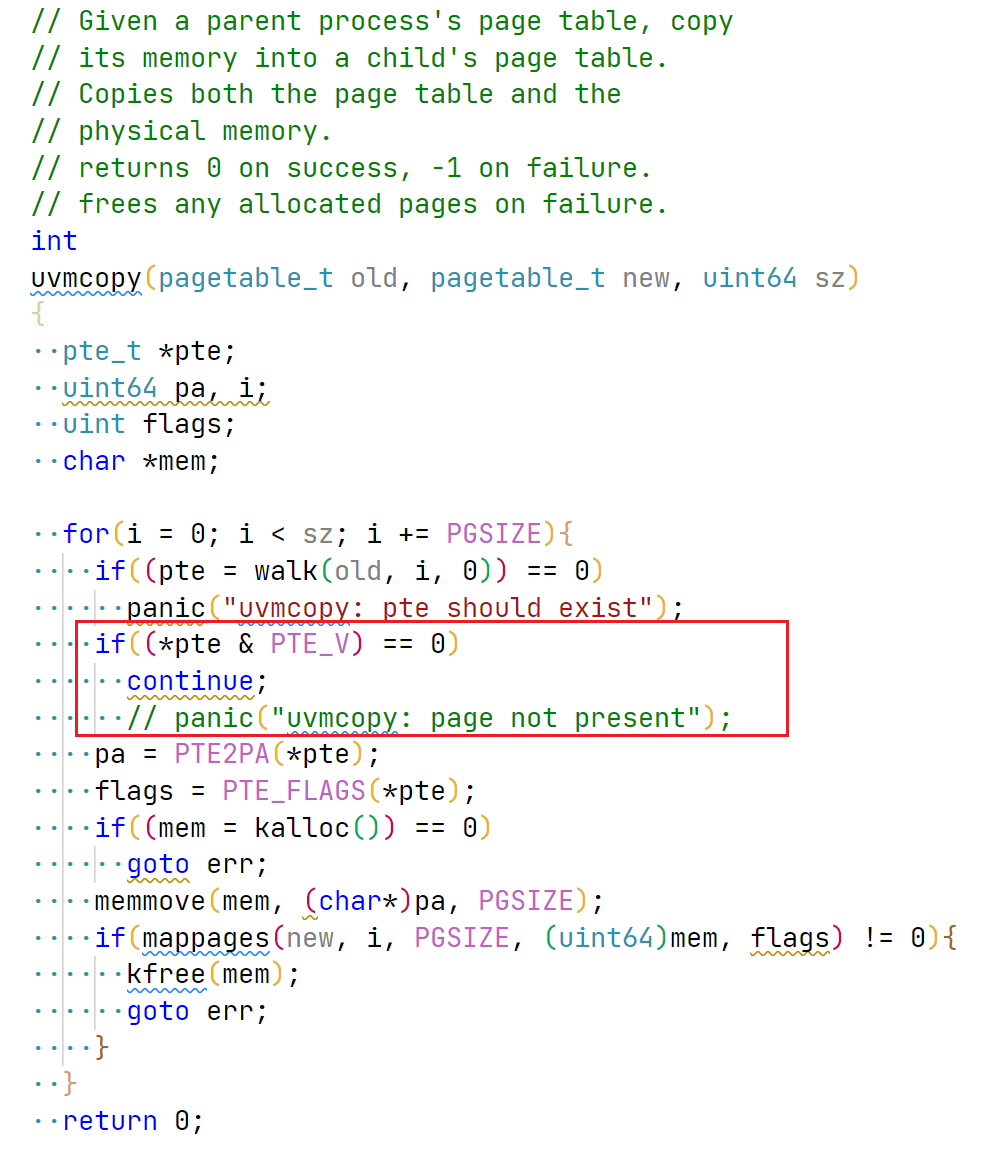
image-20220609135558496
调整 exit, 释放进程未主动释放的 vma:
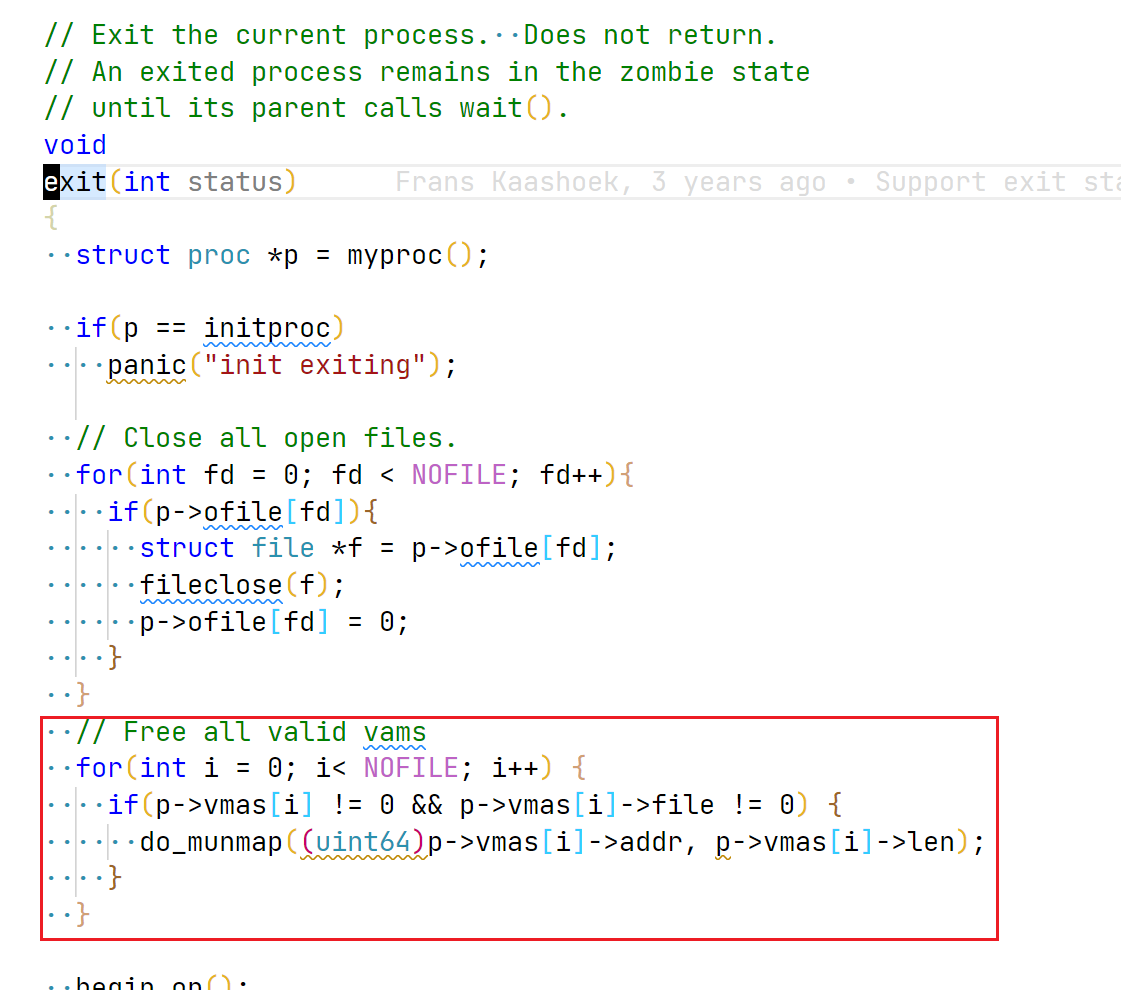
image-20220609135338868
** 修改 main,** 完成对全局 vma_table 的初始化:

image-20220609135707246
至此完成 mmap lab,执行 mmaptest 和 usertests 检验是否通过。
3. Linux 中 mmap-read 和 read 对比 ·
本节是对 mmap 方式的读取和 read 系统调用的一点感悟。仅为个人理解,可能有误,欢迎指正。
以下探讨针对 Linux 实现,并不是 xv6 中的实现。
网络上充斥着大量对 mmap 的误解,认为 mmap 方式的读取性能一定比 read 系统调用的性能好,实际上并不是的。甚至在大数据量下的随机读,mmap 性能要更差于 read 系统调用。
一种最通用的说法是,用户空间发起 read 系统调用读取请求,数据存在着两次拷贝,一次是从磁盘拷贝到内核空间(page cache) 中,另一次是从 page cache 拷贝到用户空间中,所以存在两次拷贝。而 mmap 由于读取时,可以直接将 vma 映射绑定到 page cache 中,减少了一次从 page cache 到用户空间的页拷贝(即 mmap 读取时,仅需从磁盘拷贝到内核空间 (page cache))。 相比之下,似乎 mmap 更快,毕竟减少了一次数据拷贝。
但其实不然,mmap 需要依赖 page fault 、修改页表 pte 、 invalidate TLB,这些开销是很大的。所以需要在 “多拷贝一次 page” 与 “ page fault, 修改页表,invalidate TLB” 之间做 trade off. 看哪边的成本更高。
最后谈谈个人经历:之前阅读过 LevelDB 系统源码,LevelDB 底层默认采用 mmap 的方式随机读,而与此对标的 RocksDB 底层默认采用 read 的方式随机读(具体而言是 pread)。 在实现我个人的系统时,对 mmap 和 read 两种读方式都做了测试。结果发现 read 形式的随机读性能是 mmap 方式的随机读性能的 3 倍左右。
4. 总结 ·
mmap,曾经困扰我很久的概念。在这个 lab 之后,对其有了更深的理解与感悟。

